| Reaction Details |
|---|
 | Report a problem with these data |
| Target | Nociceptin receptor |
|---|
| Ligand | BDBM50335571 |
|---|
| Substrate/Competitor | n/a |
|---|
| Meas. Tech. | ChEMBL_714495 (CHEMBL1659153) |
|---|
| Ki | 6.6±n/a nM |
|---|
| Citation |  Hayashi, S; Nakata, E; Morita, A; Mizuno, K; Yamamura, K; Kato, A; Ohashi, K Discovery of {1-[4-(2-{hexahydropyrrolo[3,4-c]pyrrol-2(1H)-yl}-1H-benzimidazol-1-yl)piperidin-1-yl]cyclooctyl}methanol, systemically potent novel non-peptide agonist of nociceptin/orphanin FQ receptor as analgesic for the treatment of neuropathic pain: design, synthesis, and structure-activity rela Bioorg Med Chem18:7675-99 (2010) [PubMed] Article Hayashi, S; Nakata, E; Morita, A; Mizuno, K; Yamamura, K; Kato, A; Ohashi, K Discovery of {1-[4-(2-{hexahydropyrrolo[3,4-c]pyrrol-2(1H)-yl}-1H-benzimidazol-1-yl)piperidin-1-yl]cyclooctyl}methanol, systemically potent novel non-peptide agonist of nociceptin/orphanin FQ receptor as analgesic for the treatment of neuropathic pain: design, synthesis, and structure-activity rela Bioorg Med Chem18:7675-99 (2010) [PubMed] Article |
|---|
| More Info.: | Get all data from this article, Assay Method |
|---|
| |
| Nociceptin receptor |
|---|
| Name: | Nociceptin receptor |
|---|
| Synonyms: | KOR-3 | Kappa-type 3 opioid receptor | Mu-type opioid receptor (Mu) | NOP | Nociceptin Receptor (ORL1 Receptor) | Nociceptin receptor (NOP) | Nociceptin receptor (ORL-1) | Nociceptin receptor (ORL1) | Nociceptin/Orphanin FQ, NOP receptor | OOR | OPIATE ORL-1 | OPRL1 | OPRL1 protein | OPRX_HUMAN | ORL1 | ORL1 receptor | Opioid receptor like-1 | Orphanin FQ receptor | Orphanin FQ receptor (ORL1) | P41146 |
|---|
| Type: | G Protein-Coupled Receptor (GPCR) |
|---|
| Mol. Mass.: | 40702.87 |
|---|
| Organism: | Homo sapiens (Human) |
|---|
| Description: | P41146 |
|---|
| Residue: | 370 |
|---|
| Sequence: | MEPLFPAPFWEVIYGSHLQGNLSLLSPNHSLLPPHLLLNASHGAFLPLGLKVTIVGLYLA
VCVGGLLGNCLVMYVILRHTKMKTATNIYIFNLALADTLVLLTLPFQGTDILLGFWPFGN
ALCKTVIAIDYYNMFTSTFTLTAMSVDRYVAICHPIRALDVRTSSKAQAVNVAIWALASV
VGVPVAIMGSAQVEDEEIECLVEIPTPQDYWGPVFAICIFLFSFIVPVLVISVCYSLMIR
RLRGVRLLSGSREKDRNLRRITRLVLVVVAVFVGCWTPVQVFVLAQGLGVQPSSETAVAI
LRFCTALGYVNSCLNPILYAFLDENFKACFRKFCCASALRRDVQVSDRVRSIAKDVALAC
KTSETVPRPA
|
|
|
|---|
| BDBM50335571 |
|---|
| n/a |
|---|
| Name | BDBM50335571 |
|---|
| Synonyms: | CHEMBL1650845 | {1-[4-(2-{5-Benzylhexahydropyrrolo[3,4-c]pyrrol-2(1H)-yl}-1H-benzimidazol-1-yl)piperidin-1-yl]cyclooctyl}methanol |
|---|
| Type | Small organic molecule |
|---|
| Emp. Form. | C34H47N5O |
|---|
| Mol. Mass. | 541.7699 |
|---|
| SMILES | OCC1(CCCCCCC1)N1CCC(CC1)n1c(nc2ccccc12)N1CC2CN(Cc3ccccc3)CC2C1 |
|---|
| Structure | 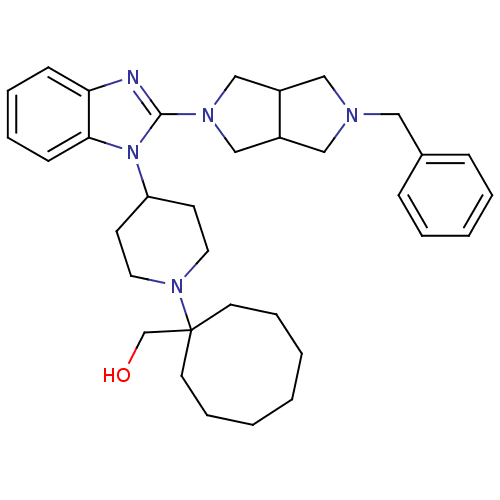
|
|---|

