

| Reaction Details | |||
|---|---|---|---|
 | Report a problem with these data | ||
| Target | 5-hydroxytryptamine receptor 2C | ||
| Ligand | BDBM50031942 | ||
| Substrate/Competitor | n/a | ||
| Ki | 1.58±n/a nM | ||
| Comments | PDSP_1230 | ||
| Citation |  Bonhaus, DW; Bach, C; DeSouza, A; Salazar, FH; Matsuoka, BD; Zuppan, P; Chan, HW; Eglen, RM The pharmacology and distribution of human 5-hydroxytryptamine2B (5-HT2B) receptor gene products: comparison with 5-HT2A and 5-HT2C receptors. Br J Pharmacol115:622-8 (1995) [PubMed] Article Bonhaus, DW; Bach, C; DeSouza, A; Salazar, FH; Matsuoka, BD; Zuppan, P; Chan, HW; Eglen, RM The pharmacology and distribution of human 5-hydroxytryptamine2B (5-HT2B) receptor gene products: comparison with 5-HT2A and 5-HT2C receptors. Br J Pharmacol115:622-8 (1995) [PubMed] Article | ||
| More Info.: | Get all data from this article | ||
| 5-hydroxytryptamine receptor 2C | |||
| Name: | 5-hydroxytryptamine receptor 2C | ||
| Synonyms: | 5-HT-1C | 5-HT-2C | 5-HT1C | 5-HT2C | 5-HT2C-INI | 5-HT2c VGI | 5-HTR2C | 5-hydroxytryptamine receptor 1C | 5-hydroxytryptamine receptor 2C (5-HT-2C) | 5-hydroxytryptamine receptor 2C (5HT-2C) | 5HT-1C | 5HT2C_HUMAN | HTR1C | HTR2C | Serotonin (5-HT3) receptor | Serotonin 2c (5-HT2c) receptor | Serotonin Receptor 2C | ||
| Type: | G Protein-Coupled Receptor (GPCR) | ||
| Mol. Mass.: | 51836.79 | ||
| Organism: | Homo sapiens (Human) | ||
| Description: | P28335 | ||
| Residue: | 458 | ||
| Sequence: |
| ||
| BDBM50031942 | |||
| n/a | |||
| Name | BDBM50031942 | ||
| Synonyms: | (6aR,9R)-4,6a,7-Trimethyl-4,6,6a,7,8,9-hexahydro-indolo[4,3-fg]quinoline-9-carboxylic acid (1-hydroxymethyl-propyl)-amide | (6aR,9R)-4,7-Dimethyl-4,6,6a,7,8,9-hexahydro-indolo[4,3-fg]quinoline-9-carboxylic acid ((S)-1-hydroxymethyl-propyl)-amide | (6aR,9R)-4-Methyl-4,6,6a,7,8,9-hexahydro-indolo[4,3-fg]quinoline-9-carboxylic acid (1-hydroxymethyl-propyl)-amide | (6aR,9R)-5,7-Dimethyl-4,6,6a,7,8,9-hexahydro-indolo[4,3-fg]quinoline-9-carboxylic acid diethylamide | (methylsergide)4,7-Dimethyl-4,6,6a,7,8,9-hexahydro-indolo[4,3-fg]quinoline-9-carboxylic acid (1-hydroxymethyl-propyl)-amide | 4,7-Dimethyl-4,6,6a,7,8,9-hexahydro-indolo[4,3-fg]quinoline-9-carboxylic acid (1-hydroxymethyl-propyl)-amide | CHEMBL1065 | METHYSERGIDE | Sansert | ||
| Type | Small organic molecule | ||
| Emp. Form. | C21H27N3O2 | ||
| Mol. Mass. | 353.458 | ||
| SMILES | CC[C@@H](CO)NC(=O)[C@H]1CN(C)[C@@H]2Cc3cn(C)c4cccc(C2=C1)c34 |r,c:24| | ||
| Structure | 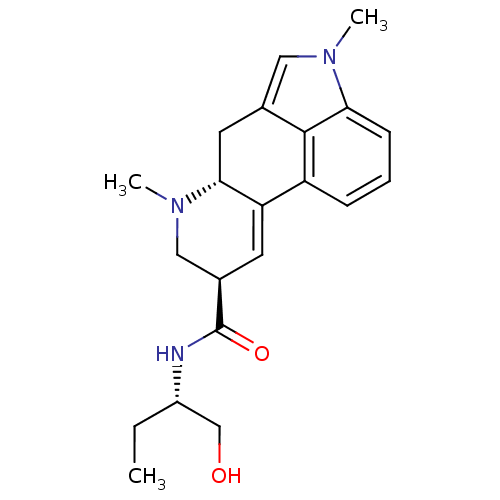
| ||