| Reaction Details |
|---|
 | Report a problem with these data |
| Target | CREB-binding protein/Histone acetyltransferase p300 |
|---|
| Ligand | BDBM50607592 |
|---|
| Substrate/Competitor | n/a |
|---|
| Meas. Tech. | ChEMBL_2262985 (CHEMBL5217996) |
|---|
| EC50 | 501±n/a nM |
|---|
| Citation |  Tian, X; Suarez, D; Thomson, D; Li, W; King, EA; LaFrance, L; Boehm, J; Barton, L; Di Marco, C; Martyr, C; Thalji, R; Medina, J; Knight, S; Heerding, D; Gao, E; Nartey, E; Cecconie, T; Nixon, C; Zhang, G; Berrodin, TJ; Phelps, C; Patel, A; Bai, X; Lind, K; Prabhu, N; Messer, J; Zhu, Z; Shewchuk, L; Reid, R; Graves, AP; McHugh, C; Mangatt, B Discovery of Proline-Based p300/CBP Inhibitors Using DNA-Encoded Library Technology in Combination with High-Throughput Screening. J Med Chem65:14391-14408 (2022) [PubMed] Article Tian, X; Suarez, D; Thomson, D; Li, W; King, EA; LaFrance, L; Boehm, J; Barton, L; Di Marco, C; Martyr, C; Thalji, R; Medina, J; Knight, S; Heerding, D; Gao, E; Nartey, E; Cecconie, T; Nixon, C; Zhang, G; Berrodin, TJ; Phelps, C; Patel, A; Bai, X; Lind, K; Prabhu, N; Messer, J; Zhu, Z; Shewchuk, L; Reid, R; Graves, AP; McHugh, C; Mangatt, B Discovery of Proline-Based p300/CBP Inhibitors Using DNA-Encoded Library Technology in Combination with High-Throughput Screening. J Med Chem65:14391-14408 (2022) [PubMed] Article |
|---|
| More Info.: | Get all data from this article, Assay Method |
|---|
| |
| CREB-binding protein/Histone acetyltransferase p300 |
|---|
| Name: | CREB-binding protein/Histone acetyltransferase p300 |
|---|
| Synonyms: | n/a |
|---|
| Type: | n/a |
|---|
| Mol. Mass.: | n/a |
|---|
| Description: | ASSAY_ID of ChEMBL is 2168996 |
|---|
| Components: | This complex has 2 components. |
|---|
| Component 1 |
| Name: | Histone acetyltransferase p300 |
|---|
| Synonyms: | EP300 | EP300_HUMAN | HIF1A/p300/CREB-binding protein | Histone acetyltransferase p300/Hypoxia-inducible factor 1-alpha | P300 |
|---|
| Type: | Protein |
|---|
| Mol. Mass.: | 264223.04 |
|---|
| Organism: | Homo sapiens (Human) |
|---|
| Description: | Q09472 |
|---|
| Residue: | 2414 |
|---|
| Sequence: | MAENVVEPGPPSAKRPKLSSPALSASASDGTDFGSLFDLEHDLPDELINSTELGLTNGGD
INQLQTSLGMVQDAASKHKQLSELLRSGSSPNLNMGVGGPGQVMASQAQQSSPGLGLINS
MVKSPMTQAGLTSPNMGMGTSGPNQGPTQSTGMMNSPVNQPAMGMNTGMNAGMNPGMLAA
GNGQGIMPNQVMNGSIGAGRGRQNMQYPNPGMGSAGNLLTEPLQQGSPQMGGQTGLRGPQ
PLKMGMMNNPNPYGSPYTQNPGQQIGASGLGLQIQTKTVLSNNLSPFAMDKKAVPGGGMP
NMGQQPAPQVQQPGLVTPVAQGMGSGAHTADPEKRKLIQQQLVLLLHAHKCQRREQANGE
VRQCNLPHCRTMKNVLNHMTHCQSGKSCQVAHCASSRQIISHWKNCTRHDCPVCLPLKNA
GDKRNQQPILTGAPVGLGNPSSLGVGQQSAPNLSTVSQIDPSSIERAYAALGLPYQVNQM
PTQPQVQAKNQQNQQPGQSPQGMRPMSNMSASPMGVNGGVGVQTPSLLSDSMLHSAINSQ
NPMMSENASVPSLGPMPTAAQPSTTGIRKQWHEDITQDLRNHLVHKLVQAIFPTPDPAAL
KDRRMENLVAYARKVEGDMYESANNRAEYYHLLAEKIYKIQKELEEKRRTRLQKQNMLPN
AAGMVPVSMNPGPNMGQPQPGMTSNGPLPDPSMIRGSVPNQMMPRITPQSGLNQFGQMSM
AQPPIVPRQTPPLQHHGQLAQPGALNPPMGYGPRMQQPSNQGQFLPQTQFPSQGMNVTNI
PLAPSSGQAPVSQAQMSSSSCPVNSPIMPPGSQGSHIHCPQLPQPALHQNSPSPVPSRTP
TPHHTPPSIGAQQPPATTIPAPVPTPPAMPPGPQSQALHPPPRQTPTPPTTQLPQQVQPS
LPAAPSADQPQQQPRSQQSTAASVPTPTAPLLPPQPATPLSQPAVSIEGQVSNPPSTSST
EVNSQAIAEKQPSQEVKMEAKMEVDQPEPADTQPEDISESKVEDCKMESTETEERSTELK
TEIKEEEDQPSTSATQSSPAPGQSKKKIFKPEELRQALMPTLEALYRQDPESLPFRQPVD
PQLLGIPDYFDIVKSPMDLSTIKRKLDTGQYQEPWQYVDDIWLMFNNAWLYNRKTSRVYK
YCSKLSEVFEQEIDPVMQSLGYCCGRKLEFSPQTLCCYGKQLCTIPRDATYYSYQNRYHF
CEKCFNEIQGESVSLGDDPSQPQTTINKEQFSKRKNDTLDPELFVECTECGRKMHQICVL
HHEIIWPAGFVCDGCLKKSARTRKENKFSAKRLPSTRLGTFLENRVNDFLRRQNHPESGE
VTVRVVHASDKTVEVKPGMKARFVDSGEMAESFPYRTKALFAFEEIDGVDLCFFGMHVQE
YGSDCPPPNQRRVYISYLDSVHFFRPKCLRTAVYHEILIGYLEYVKKLGYTTGHIWACPP
SEGDDYIFHCHPPDQKIPKPKRLQEWYKKMLDKAVSERIVHDYKDIFKQATEDRLTSAKE
LPYFEGDFWPNVLEESIKELEQEEEERKREENTSNESTDVTKGDSKNAKKKNNKKTSKNK
SSLSRGNKKKPGMPNVSNDLSQKLYATMEKHKEVFFVIRLIAGPAANSLPPIVDPDPLIP
CDLMDGRDAFLTLARDKHLEFSSLRRAQWSTMCMLVELHTQSQDRFVYTCNECKHHVETR
WHCTVCEDYDLCITCYNTKNHDHKMEKLGLGLDDESNNQQAAATQSPGDSRRLSIQRCIQ
SLVHACQCRNANCSLPSCQKMKRVVQHTKGCKRKTNGGCPICKQLIALCCYHAKHCQENK
CPVPFCLNIKQKLRQQQLQHRLQQAQMLRRRMASMQRTGVVGQQQGLPSPTPATPTTPTG
QQPTTPQTPQPTSQPQPTPPNSMPPYLPRTQAAGPVSQGKAAGQVTPPTPPQTAQPPLPG
PPPAAVEMAMQIQRAAETQRQMAHVQIFQRPIQHQMPPMTPMAPMGMNPPPMTRGPSGHL
EPGMGPTGMQQQPPWSQGGLPQPQQLQSGMPRPAMMSVAQHGQPLNMAPQPGLGQVGISP
LKPGTVSQQALQNLLRTLRSPSSPLQQQQVLSILHANPQLLAAFIKQRAAKYANSNPQPI
PGQPGMPQGQPGLQPPTMPGQQGVHSNPAMQNMNPMQAGVQRAGLPQQQPQQQLQPPMGG
MSPQAQQMNMNHNTMPSQFRDILRRQQMMQQQQQQGAGPGIGPGMANHNQFQQPQGVGYP
PQQQQRMQHHMQQMQQGNMGQIGQLPQALGAEAGASLQAYQQRLLQQQMGSPVQPNPMSP
QQHMLPNQAQSPHLQGQQIPNSLSNQVRSPQPVPSPRPQSQPPHSSPSPRMQPQPSPHHV
SPQTSSPHPGLVAAQANPMEQGHFASPDQNSMLSQLASNPGMANLHGASATDLGLSTDNS
DLNSNLSQSTLDIH
|
|
|
|---|
| Component 2 |
| Name: | CREB-binding protein |
|---|
| Synonyms: | CBP | CBP_HUMAN | CREB-binding protein (CBP) | CREB-binding protein (CREBBP) | CREBBP |
|---|
| Type: | Transcription Coactivator |
|---|
| Mol. Mass.: | 265411.66 |
|---|
| Organism: | Homo sapiens (Human) |
|---|
| Description: | Q92793 |
|---|
| Residue: | 2442 |
|---|
| Sequence: | MAENLLDGPPNPKRAKLSSPGFSANDSTDFGSLFDLENDLPDELIPNGGELGLLNSGNLV
PDAASKHKQLSELLRGGSGSSINPGIGNVSASSPVQQGLGGQAQGQPNSANMASLSAMGK
SPLSQGDSSAPSLPKQAASTSGPTPAASQALNPQAQKQVGLATSSPATSQTGPGICMNAN
FNQTHPGLLNSNSGHSLINQASQGQAQVMNGSLGAAGRGRGAGMPYPTPAMQGASSSVLA
ETLTQVSPQMTGHAGLNTAQAGGMAKMGITGNTSPFGQPFSQAGGQPMGATGVNPQLASK
QSMVNSLPTFPTDIKNTSVTNVPNMSQMQTSVGIVPTQAIATGPTADPEKRKLIQQQLVL
LLHAHKCQRREQANGEVRACSLPHCRTMKNVLNHMTHCQAGKACQVAHCASSRQIISHWK
NCTRHDCPVCLPLKNASDKRNQQTILGSPASGIQNTIGSVGTGQQNATSLSNPNPIDPSS
MQRAYAALGLPYMNQPQTQLQPQVPGQQPAQPQTHQQMRTLNPLGNNPMNIPAGGITTDQ
QPPNLISESALPTSLGATNPLMNDGSNSGNIGTLSTIPTAAPPSSTGVRKGWHEHVTQDL
RSHLVHKLVQAIFPTPDPAALKDRRMENLVAYAKKVEGDMYESANSRDEYYHLLAEKIYK
IQKELEEKRRSRLHKQGILGNQPALPAPGAQPPVIPQAQPVRPPNGPLSLPVNRMQVSQG
MNSFNPMSLGNVQLPQAPMGPRAASPMNHSVQMNSMGSVPGMAISPSRMPQPPNMMGAHT
NNMMAQAPAQSQFLPQNQFPSSSGAMSVGMGQPPAQTGVSQGQVPGAALPNPLNMLGPQA
SQLPCPPVTQSPLHPTPPPASTAAGMPSLQHTTPPGMTPPQPAAPTQPSTPVSSSGQTPT
PTPGSVPSATQTQSTPTVQAAAQAQVTPQPQTPVQPPSVATPQSSQQQPTPVHAQPPGTP
LSQAAASIDNRVPTPSSVASAETNSQQPGPDVPVLEMKTETQAEDTEPDPGESKGEPRSE
MMEEDLQGASQVKEETDIAEQKSEPMEVDEKKPEVKVEVKEEEESSSNGTASQSTSPSQP
RKKIFKPEELRQALMPTLEALYRQDPESLPFRQPVDPQLLGIPDYFDIVKNPMDLSTIKR
KLDTGQYQEPWQYVDDVWLMFNNAWLYNRKTSRVYKFCSKLAEVFEQEIDPVMQSLGYCC
GRKYEFSPQTLCCYGKQLCTIPRDAAYYSYQNRYHFCEKCFTEIQGENVTLGDDPSQPQT
TISKDQFEKKKNDTLDPEPFVDCKECGRKMHQICVLHYDIIWPSGFVCDNCLKKTGRPRK
ENKFSAKRLQTTRLGNHLEDRVNKFLRRQNHPEAGEVFVRVVASSDKTVEVKPGMKSRFV
DSGEMSESFPYRTKALFAFEEIDGVDVCFFGMHVQEYGSDCPPPNTRRVYISYLDSIHFF
RPRCLRTAVYHEILIGYLEYVKKLGYVTGHIWACPPSEGDDYIFHCHPPDQKIPKPKRLQ
EWYKKMLDKAFAERIIHDYKDIFKQATEDRLTSAKELPYFEGDFWPNVLEESIKELEQEE
EERKKEESTAASETTEGSQGDSKNAKKKNNKKTNKNKSSISRANKKKPSMPNVSNDLSQK
LYATMEKHKEVFFVIHLHAGPVINTLPPIVDPDPLLSCDLMDGRDAFLTLARDKHWEFSS
LRRSKWSTLCMLVELHTQGQDRFVYTCNECKHHVETRWHCTVCEDYDLCINCYNTKSHAH
KMVKWGLGLDDEGSSQGEPQSKSPQESRRLSIQRCIQSLVHACQCRNANCSLPSCQKMKR
VVQHTKGCKRKTNGGCPVCKQLIALCCYHAKHCQENKCPVPFCLNIKHKLRQQQIQHRLQ
QAQLMRRRMATMNTRNVPQQSLPSPTSAPPGTPTQQPSTPQTPQPPAQPQPSPVSMSPAG
FPSVARTQPPTTVSTGKPTSQVPAPPPPAQPPPAAVEAARQIEREAQQQQHLYRVNINNS
MPPGRTGMGTPGSQMAPVSLNVPRPNQVSGPVMPSMPPGQWQQAPLPQQQPMPGLPRPVI
SMQAQAAVAGPRMPSVQPPRSISPSALQDLLRTLKSPSSPQQQQQVLNILKSNPQLMAAF
IKQRTAKYVANQPGMQPQPGLQSQPGMQPQPGMHQQPSLQNLNAMQAGVPRPGVPPQQQA
MGGLNPQGQALNIMNPGHNPNMASMNPQYREMLRRQLLQQQQQQQQQQQQQQQQQQGSAG
MAGGMAGHGQFQQPQGPGGYPPAMQQQQRMQQHLPLQGSSMGQMAAQMGQLGQMGQPGLG
ADSTPNIQQALQQRILQQQQMKQQIGSPGQPNPMSPQQHMLSGQPQASHLPGQQIATSLS
NQVRSPAPVQSPRPQSQPPHSSPSPRIQPQPSPHHVSPQTGSPHPGLAVTMASSIDQGHL
GNPEQSAMLPQLNTPSRSALSSELSLVGDTTGDTLEKFVEGL
|
|
|
|---|
| BDBM50607592 |
|---|
| n/a |
|---|
| Name | BDBM50607592 |
|---|
| Synonyms: | CHEMBL5219466 |
|---|
| Type | Small organic molecule |
|---|
| Emp. Form. | C23H26ClN3O3 |
|---|
| Mol. Mass. | 427.924 |
|---|
| SMILES | COc1ccc(NC(=O)[C@H]2CCCN2C(=O)C2(CCCC2)c2cccc(Cl)c2)nc1 |r| |
|---|
| Structure | 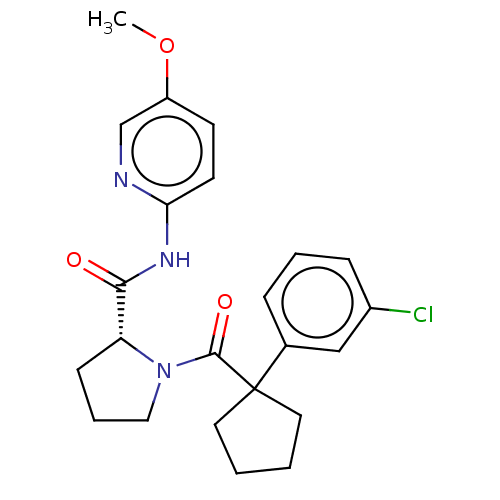
|
|---|

